Agent 的核心代码不到 20 行,但大多数团队搭不稳
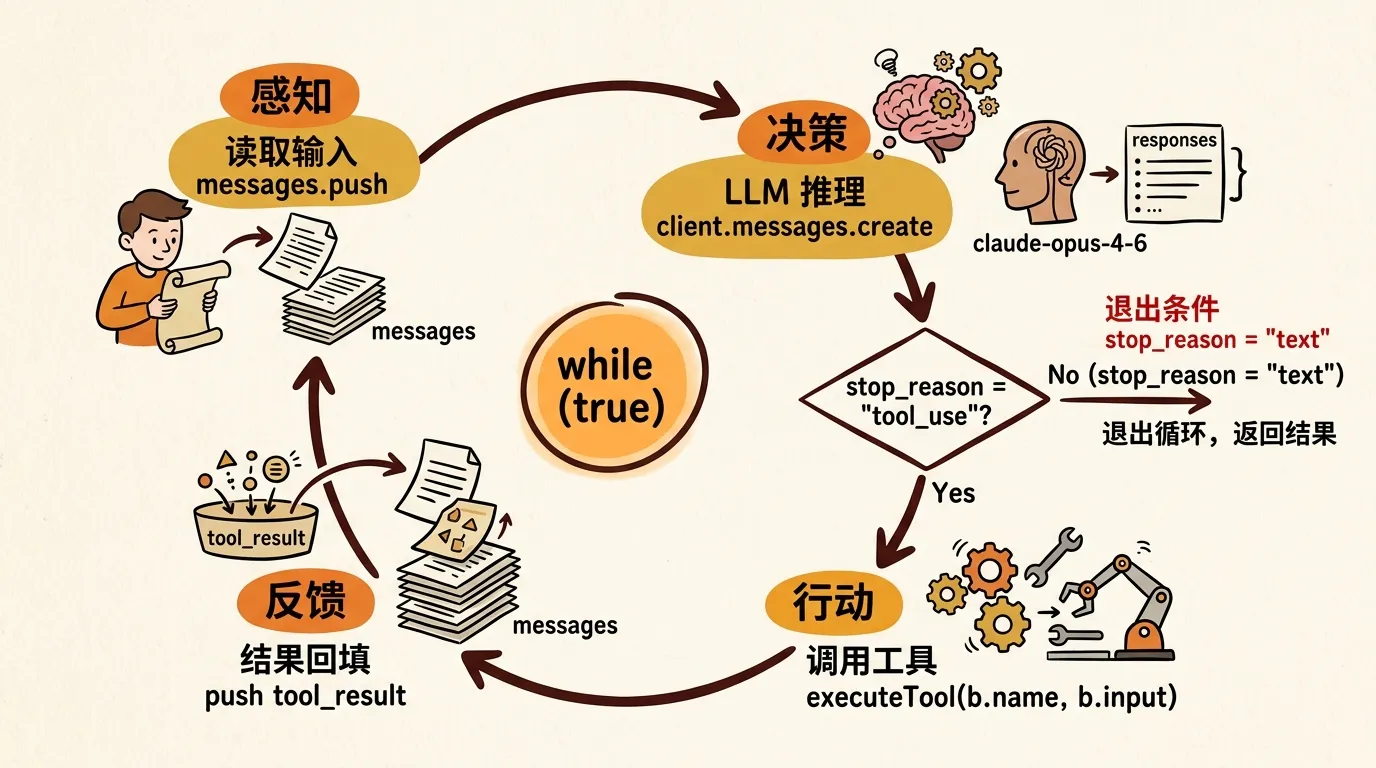
Agent Loop 的核心实现逻辑抽象出来不到 20 行代码:
const messages = [{ role: "user", content: userInput }];
while (true) {
const response = await client.messages.create({
model: "claude-opus-4-6",
max_tokens: 8096,
tools: toolDefinitions,
messages,
});
if (response.stop_reason === "tool_use") {
const toolResults = await Promise.all(
response.content
.filter((b) => b.type === "tool_use")
.map(async (b) => ({
type: "tool_result",
tool_use_id: b.id,
content: await executeTool(b.name, b.input),
}))
);
messages.push({ role: "assistant", content: response.content });
messages.push({ role: "user", content: toolResults });
} else {
return response.content.find((b) => b.type === "text")?.text ?? "";
}
}一个 while 循环,四个阶段不断重复:感知(读取输入)、决策(模型推理)、行动(调用工具)、反馈(结果回填),直到模型返回纯文本为止。
看过不少开源实现和官方 SDK,结构都差不多。从最小 demo 一路扩展到支持子 Agent、上下文压缩、Skills 加载,主循环基本不用动。新能力只通过三种方式接入:扩展工具集、调整系统提示结构、把状态外化到文件或数据库。模型负责推理,外部系统负责状态和边界,分工一旦确定,核心循环就很少需要改。
就这么一个循环。
那为什么 Agent 还是跑不稳
很多人用 Agent 做项目,都经历过这个阶段:改了 prompt 好了两天,过几天又出问题,换个模型感觉没什么差别,反复调来调去效果时好时坏。
问题大概率不在 Loop,在 Harness。
Harness 是围绕 Agent 构建的测试、验证与约束基础设施,至少包括四个部分:验收基线(怎么判断做对了)、执行边界(哪些操作不允许)、反馈信号(怎么知道做错了)、回退手段(错了怎么恢复)。
模型当然重要,但决定系统能不能稳定运行的,往往是这些外围工程条件。这个判断在代码编写这类高可验证任务上最成立,但在开放式研究、多轮协商这类弱验证任务里,模型上限本身仍然更关键。
有一个案例很说明问题
3 个工程师,5 个月,写了将近 100 万行代码,1500 个 PR,传统速度的 10 倍。
这个速度不是靠模型强,是几个工程决策做对了:
Agent 看不到的内容等于不存在。知识必须存在于代码库本身,外部文档对运行中的 Agent 不可见。AGENTS.md 只保留约 100 行索引,细节拆到各目录按需引用。
约束编码化而非文档化。写在文档里的规范很容易被忽略,编进 Linter、类型系统或 CI 规则里的约束才具备可执行性。架构分层靠自定义 Linter 机械强制,不靠人工 Review。
Agent 端到端自主完成任务。从复现 Bug、实现修复、驱动验证,到开 PR、处理 Review 反馈、自主合并,全链路不需要人介入。整套可观测性栈按任务临时创建、完成即销毁,Agent 直接查询系统状态来验证修改是否生效。
这些做法有一个共同特征:让”对错”有机器可以执行的判断标准,而不是靠人盯。
怎么判断自己的 Agent 适不适合跑起来
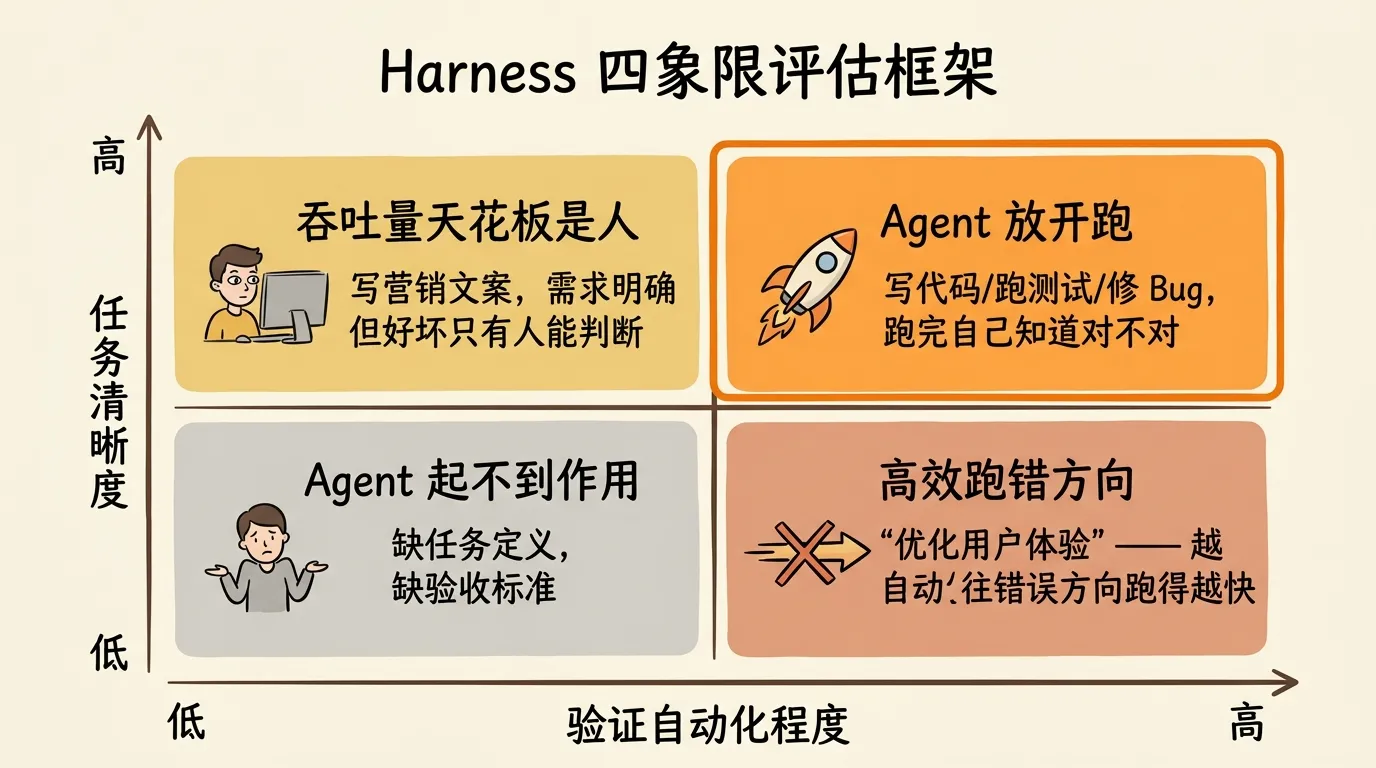
用两个维度画一个四象限:纵轴是任务清晰度,横轴是验证自动化程度。
右上角是最理想的位置:目标明确,结果可以自动验证。写代码、跑测试、修 Bug 这类任务天然在这个区域,Agent 可以放开跑,跑完自己就知道对不对。
左上角,任务清楚但验收还得人盯。比如写一段营销文案,需求很明确,但”写得好不好”只有人能判断。这个区域的吞吐量天花板就是人的审查速度,Agent 再快也得等人看。
右下角最危险:有自动化反馈但目标模糊。比如让 Agent “优化用户体验”,它会一直跑一直改,每次测试都通过,但方向可能从头就是错的。系统越自动化,往错误方向跑得越快。
左下角两者都缺,Agent 基本起不到作用。
Harness 要做的事情,就是把任务往右上角推。没有现成的自动化验收?写一个。目标不够清晰?先把验收标准定义出来,再让 Agent 动手。很多团队的问题不是 Agent 不够聪明,是从来没有定义过”做对了”长什么样。
调试 Agent 的正确顺序
Agent 出了问题,大多数团队第一反应是换模型或者改 prompt。但更有效的排查顺序是反过来的:
先看验收标准有没有。如果连”做对了”的定义都没有,调什么都是碰运气。
再看工具定义准不准。多数工具选择错误不是模型能力问题,是工具描述写得含糊,模型不知道该选哪个。
最后才考虑换模型。到这一步的时候,往往前两步已经解决了大部分问题。
这是「如何构建 Agent」系列第一篇,后续会继续拆上下文工程、工具设计、记忆与自主度。
如果这篇对你有用,转发给同样在做 Agent 的人,或者关注我,下一篇继续。