
AI 为什么时而神准时而乱说?大模型的六个底层机制
你知道 AI 是怎么回答你的吗?
不是查数据库,不是在”脑子里”思考。大模型做的事情只有一件:猜下一个词。每次猜一个,猜完再猜,直到回答结束。
就这样。
正是这一件事,解释了 AI 所有奇怪的行为。为什么写代码很准,引用偏门论文会编造;为什么长会话之后开始”降智”;为什么同一个问题今天和明天答案不一样。
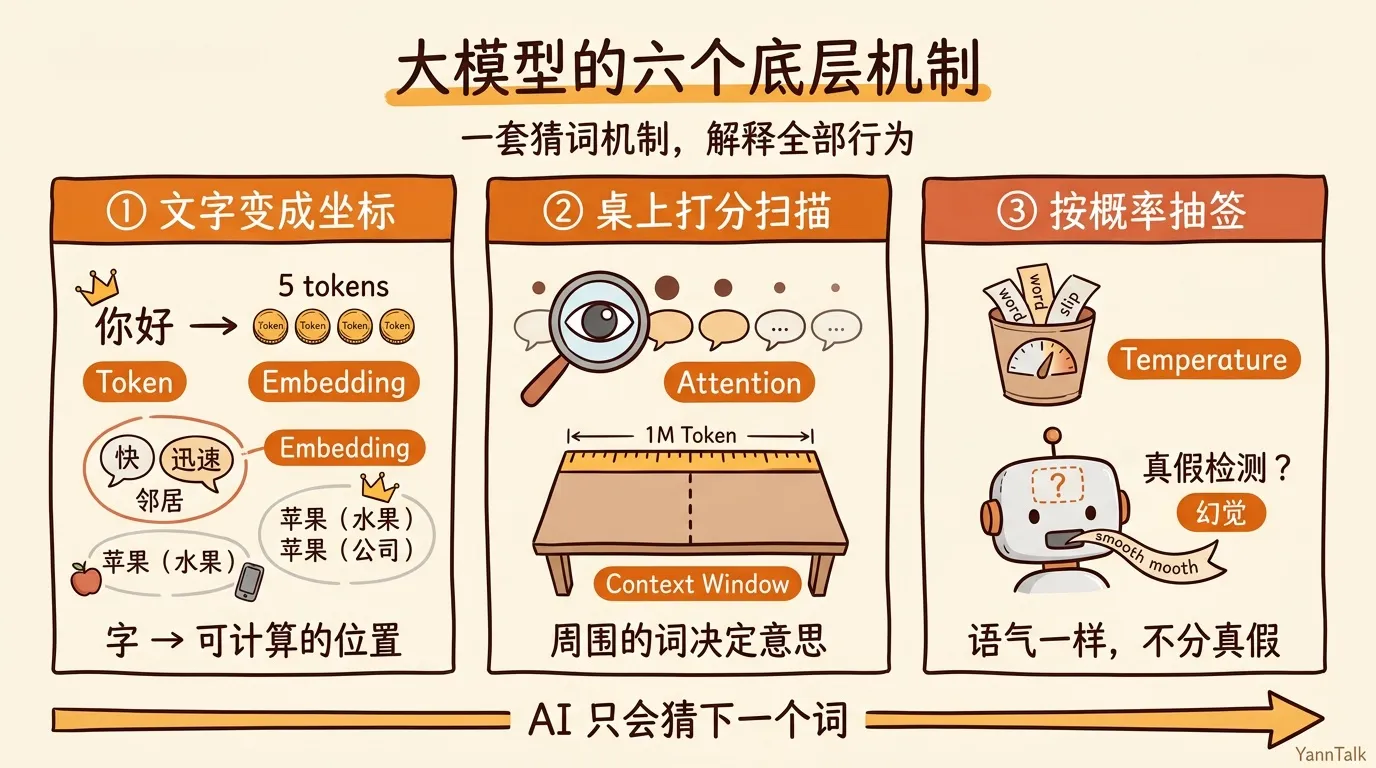
背后是六个机制串成的链:先把文字变成坐标(Token、Embedding),在桌上打分扫描(Attention、Context Window),按概率抽下一个词(Temperature、幻觉)。下面一段一段拆。
文字先变成坐标
AI 看不懂文字。
你输入的每一个字,在进入模型之前,要先翻译成数字。这些数字叫 Token。“你好,世界”翻译成 5 个数字,“Hello, world”翻译成 3 个。中文比英文用 Token 更”贵”:100 字中文大概消耗 150-200 个 Token,比同等内容的英文多出 50%。你用 AI 服务被按 Token 计费,原因就在这里。
但数字只是编号,“1234”和”1235”没有任何关系,AI 没法从编号里知道”快”和”迅速”是一回事。所以每个 Token 还要再做一步:变成坐标(Embedding)。
想象一张超大的语义地图,每个词都有自己的位置。“快”和”迅速”是邻居,“苹果水果”和”苹果公司”住在同一片区域但不在同一栋楼。AI 理解词义,靠的是看它住在地图哪里,不是靠背规则。
这个地图还能做方向计算:把”国王”的坐标减去”男人”再加上”女人”,结果落在”女王”旁边。向量算术。
上下文窗口的盲区
拿到坐标序列之后,AI 用**注意力(Attention)处理上下文关系:读每个词的时候,顺带扫一眼整个序列,给其他词打分:谁和我最相关?
“银行”和”取钱”放在一起,注意力集中在金融含义;和”路边”放在一起,注意力转向地理含义。每个词的意思由周围决定,不是孤立计算的。
但注意力能覆盖的范围有上限,叫上下文窗口(Context Window)。可以理解成 AI 的工作桌:桌子有多大,它能同时看多少东西。Claude Opus 4.7 的桌子是 1M Token,听起来很大,但官方建议过半就开始压缩上下文。超出桌子范围的内容,不是”记不清了”,是物理上不存在于视野里。
桌子看起来很大,但消耗比你想的快。系统设置、工具定义、历史对话、每轮输入输出,全部占桌面。写代码写了三小时,桌子上堆满了中间过程,最开始定好的架构约定,早就被推到了角落甚至掉下去了。
还有一个问题更隐蔽:桌子中间的东西,AI 最容易忽视。放在开头和结尾的内容,注意力权重更高。你在会话第 50 轮说的某个约定,远不如你在第 1 轮说的同一件事更被”听进去”。
**AI 越聊越降智,不是模型变差了,是桌子被杂物填满。有用的东西,被推到了边缘。
AI 的幻觉从哪来
每次生成下一个词时,AI 算出所有候选词的概率分布,然后按概率抽签。这里有个叫 Temperature 的参数,控制签桶里的签有多均匀。
调低,高概率的签变多,输出稳定可复现,写代码和数学推理适合这里。调高,签的分布变均匀,低概率的词也有机会被选中,头脑风暴和创意文案更合适。大多数产品默认值在 0.7 左右。
同一问题今天和明天答案略有不同,就是 Temperature 大于零的结果,不是故障。随机性是功能,不是 bug。
还有一件事。AI 没有任何模块在检查”我说的是真的吗”。
它只会猜词。猜得流畅,就继续猜,不管内容对不对。训练数据里反复出现的知识(代码语法、基础常识、主流概念),猜得很准。但遇到太具体的引用、太冷门的知识、训练截止日期之后的事,数据稀疏,它不会说”我不知道”,而是用听起来对的语言把空白填上。语气和说准确内容时一模一样。
这就是幻觉(Hallucination)。“爱因斯坦 1987 年在北京大学发表了一场著名演讲……”措辞严谨,语气确定,但爱因斯坦 1955 年就已经去世了。它不是在骗你。它压根没有”真假”这个概念,只有”流畅”。
六个机制就是这些。
把文字变成坐标,在有限的桌子上打分扫描,按概率抽一个词,继续。没有魔法。
**AI 的错和 AI 的准,来自同一个机制。知道它怎么工作,什么时候该信、什么时候得查,心里就有数了。
阶段二讲怎么在这套机制上把 AI 用好:Prompt 设计、RAG、Agent。关注 YannTalk,下一篇继续。