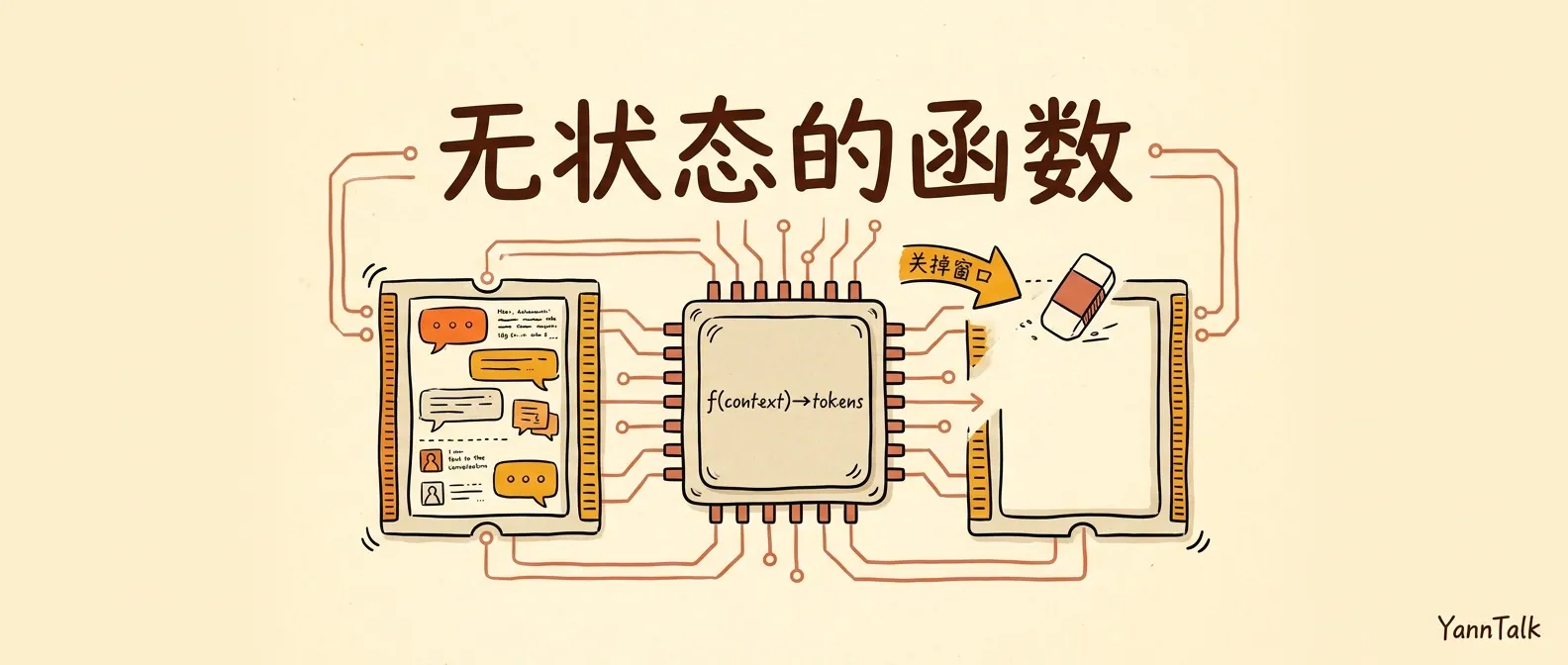
LLM 是一个无状态纯函数:Harness 工程的第一条公理
那天下午我在重构一段代码。
逻辑本来就绕,改法来来回回对焦了好几轮,最后磨出了一个都认可的思路。
我去倒了杯水。
回来开了个新窗口,打算接着写实现。把刚才定的思路说了一遍。
它客气地说「好的」,然后问我那段逻辑想怎么处理。
等一下,我刚才说了。
重说一遍,往下走两步,它又问了同一个问题。
切回原来那个对话。同一个问题,它接得毫无破绽,好像那个方案本来就在那里。再新建一个窗口,又是个陌生人。
左边栏里,原来的对话好好躺着,一字不差,没丢。同一个模型,同一台服务器,刚刚还跟我一起磨方案的那个「它」——哪儿去了?
它不是在记,是在读
先别急着下结论,换个角度想。你跑一个脚本,跑完进程退出。下次再跑,从头开始,上次算的东西全没了。除非你主动写进了文件。
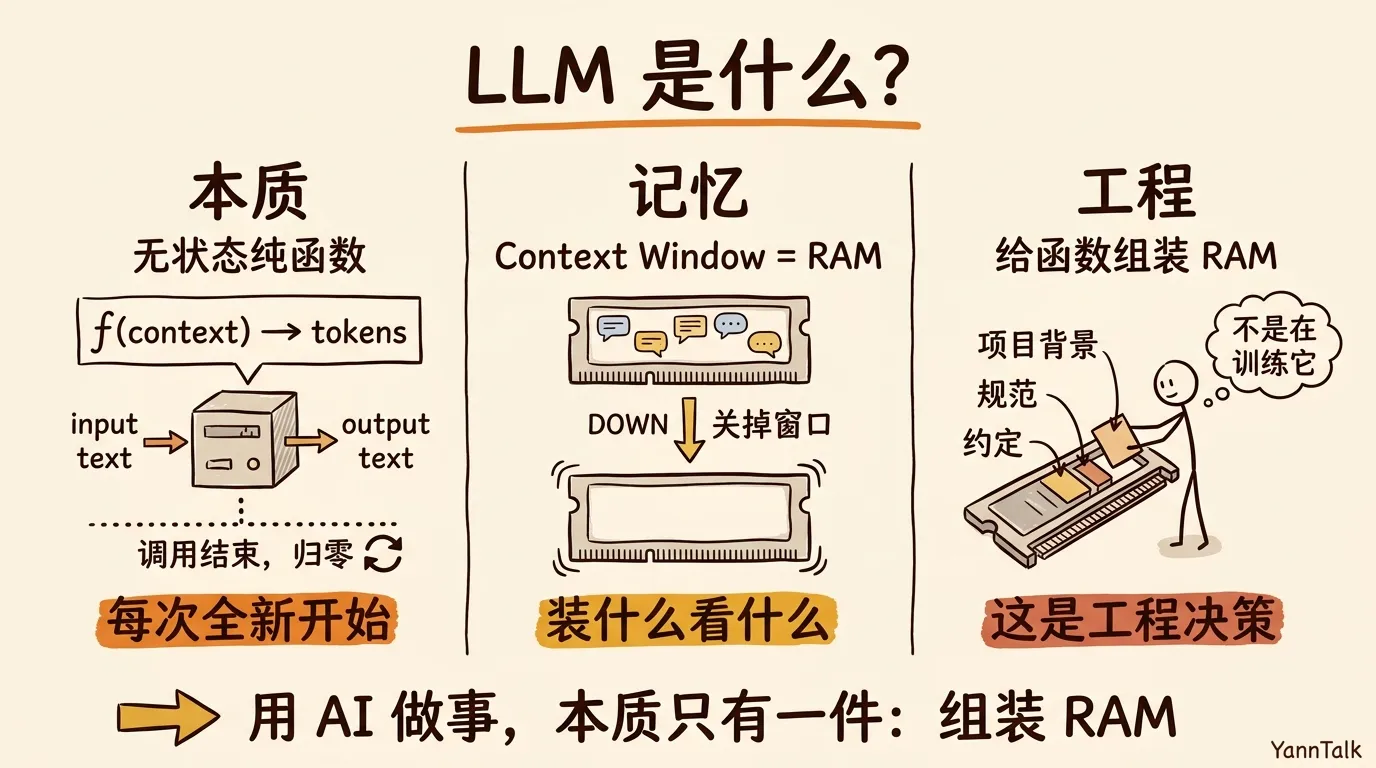
LLM 就是这种东西。一个函数:f(context) → tokens。喂进去一段文字,吐出来一段文字。调用结束,状态归零,下一次调用物理上是一次全新的开始。
AI 工程圈常被引用的 Simon Willison 说过一句很直白的话:LLMs 是无状态的函数调用。每次执行,都从同一个空白状态开始。完全没有意义去「告诉」模型什么、期望它在未来对话中记住。
第一次读,有点反直觉。但想想前面那个程序的例子就顺了:模型自己不存东西,它没有「昨天」这个概念。那问题就来了:既然什么都不记得,为什么同一个对话里,它又明明接得住上下文?
Karpathy 给过一个类比,挺好用。LLM 像 CPU,对话窗口(context window)像 RAM。CPU 负责算,RAM 装它当前要算的东西。你每在对话框里敲一条新消息,整个窗口里已经堆着的字符,加上你这条新消息,会被整包塞给 CPU 算一次,算完吐一段回复。下一轮,整包再塞一次,再算一次。
听起来有点笨,但事实就是这样。它「记得」上一句你说了什么,不是因为它真记住了,是因为上一句还摆在 RAM 里,跟着这一次的输入一起被读了进去。RAM 里有什么,它就看得见什么,RAM 之外,什么都不存在。
关掉窗口,那块 RAM 就清了。下次打开,是一块全新的 RAM,跟昨天那块,物理上不是同一块。
给它什么,它就是什么
想通这一层,以前一堆别扭的现象,突然就都讲通了。
Claude Code 聊久了会「失忆」,对话越长,早期定的约定越容易失效。以前以为是模型开小差,现在再看,早期那些约定,是被后面塞进来的新内容,从 RAM 里挤出去了。RAM 就那么大,进得来新的,就得挤走旧的。
告诉 AI 一次偏好,下次开窗口得重说一遍。AI 用久了不会越来越懂你,每一次对话它都是第一次见你。
遇到它做得烂,第一反应不该是「这模型不行」,该先问一句:RAM 里给够了吗?
这也解释了一件事。你有没有注意过,Claude Code 每次新对话启动,都会自动读一个叫 CLAUDE.md 的文件?项目背景、代码规范、团队约定,全写在里面。
不是什么高级设计。Anthropic 自己也接受了这个物理限制:既然跨对话没记忆,那就每次新对话启动,自动把该知道的东西重新塞回 RAM 里。绕不开,就不绕,正面处理。
这条想明白,再回头看你平时跟 AI 打交道的方式,大多数动作的性质都变了。你不是在「训练」它,你是在往它眼前那块 RAM 里,摆你希望它看见的东西。摆什么、摆多少、怎么排、什么时候清,这些不是用户技巧,是 AI 工程的决策。
用 AI 做事,本质只有一件:给这个无状态的函数,组装一块它用得上的 RAM。
那稳定的「人格」从哪儿来:AI 工程的下一层
不过还有个问题没答。既然每次都是空 RAM,Claude Code 为什么每次打开,都带着一种稳定的「人格」?固定的工作方式,一以贯之的语气。
不可能是巧合。在你敲下第一条消息之前,已经有人,提前往那块 RAM 里塞了东西。下一篇,看看塞的是什么。
这个系列,打算一层一层把围绕这个无状态函数搭起来的 harness 拆开看。觉得有用,转发给也在用 AI 写代码的朋友。觉得这个框架值得继续看,点个关注。有想法或者不同意的地方,留言聊聊。