
黄仁勋:AGI已实现,未来每个木匠都是程序员
黄仁勋是 NVIDIA 联合创始人兼 CEO,执掌公司 33 年,将一家显卡公司做成了全球市值最高的 AI 基础设施公司。
这期是 Lex Fridman Podcast 第 494 期,2026 年 3 月发布,时长 2 小时 25 分钟。两个半小时里,黄仁勋几乎把 AI 的现状、未来和 NVIDIA 的底牌全摊开了。其中最具争议的一句:“我认为我们已经实现了 AGI。”
【注:Lex Fridman 是 MIT 研究员,主持同名播客,以深度采访科技界和学术界顶尖人物著称,在工程师群体中影响力极高,类似中文世界的“硬核技术领域的许知远”。】
原文链接:https://www.youtube.com/watch?v=vif8NQcjVf0
要点速览
- 黄仁勋 AGI 定义:不是科幻,是“AI 能独立创造数亿美元商业价值”,他认为已实现
- 编程人口将从 3000 万增到 10 亿,未来每个木匠都是程序员
- 你的工作是“任务”还是“目标”?这个区分决定会不会被 AI 替代
- AI 有四个 Scaling Law 阶段,测试时计算和智能体扩展是当前重心
- 计算机不再是仓库,是工厂,Token 就是产品
- NVIDIA 曾为 CUDA 赌上全部利润,市值从 80 亿跌到 15 亿
- 黄仁勋的压力管理:系统性遗忘,像 AI 训练一样学会有选择地忘记
以下按访谈核心话题分 7 个部分展开。
“我认为 AGI 已经实现了”
Lex 给 AGI 设了一个很高的门槛:如果 AGI 是一个能替代你、创立并运营一家十亿美元公司的 AI,我们离它还有多远?
“I think it’s now. I think we’ve achieved AGI.” (我认为就是现在。我认为我们已经实现了 AGI。)
他的逻辑不复杂:现在的 AI 智能体已经能写代码、开发应用、创造几千万甚至数亿美元的商业价值。按照“能独立完成专业任务并产生商业回报”这个标准,AGI 不是未来,是现在。
这跟学术界的 AGI 定义差别很大。学术界讨论的是“在所有认知任务上达到人类水平”,黄仁勋说的是“能干活、能赚钱”。你可以不同意他的定义,但很难否认他描述的现象正在发生。
【注:AGI(通用人工智能)的定义目前没有统一标准。OpenAI 将其定义为“在大多数经济活动中超越人类的系统”,DeepMind 提出了六级分类框架。黄仁勋用的是更偏商业实用性的标准。】
编程不会消亡,但程序员将从 3000 万变成 10 亿
Lex 紧接着追问:那程序员怎么办?
黄仁勋没说“程序员会失业”,他说的是“编程”这件事会被重新定义。
以前编程是写 Python、写 Java,未来编程是用自然语言描述你要什么。他管这个叫”specifying the specification”,用人话下达需求规范。当英语(或任何自然语言)变成编程语言,门槛就不存在了。
“We just went from 30 million to probably 1 billion. Every carpenter in the future will be a coder.” (我们刚刚从 3000 万人跳到了 10 亿人。未来每个木匠都是程序员。)
3000 万是目前全球的专业开发者数量。10 亿是他认为用自然语言“编程”的人口规模。
这不是威胁,是扩展。写代码的人不会变少,但“程序员”这个词的含义会彻底变掉。
你的工作是“任务”还是“目标”
这是整段访谈里最值得反复咀嚼的一个框架。
“The purpose of your job and the tasks and the tools that you use to do your job are related, not the same.” (你工作的目标,和你完成工作所用的任务与工具,有关联,但不是一回事。)
AI 自动化的是“任务”,不是“目标”。关键在于你怎么定义自己的工作。
他举了放射科医生的例子。 2019 年前后,AI 的图像识别就已经达到超人类水平。当时所有人都说放射科医生要失业了。结果呢?没有失业,需求量反而更大了。AI 提高了读片效率,医院能接更多患者,需要更多医生来做判断和决策。
“If your job is the task then you’re very highly going to be disrupted. If your job’s purpose includes certain tasks then it’s vital that you go learn how to use AI to automate those tasks.” (如果你的工作就是那个任务本身,你大概率会被颠覆。如果你的工作目标包含了某些任务,那你必须学会用 AI 来自动化这些任务。)
他还给了一个直白的招聘标准:
“If we were to hire a new college graduate today… I would hire the one who’s expert in using AI.” (如果今天要招一个应届生,一个不懂 AI,一个擅长用 AI,我选后者。)
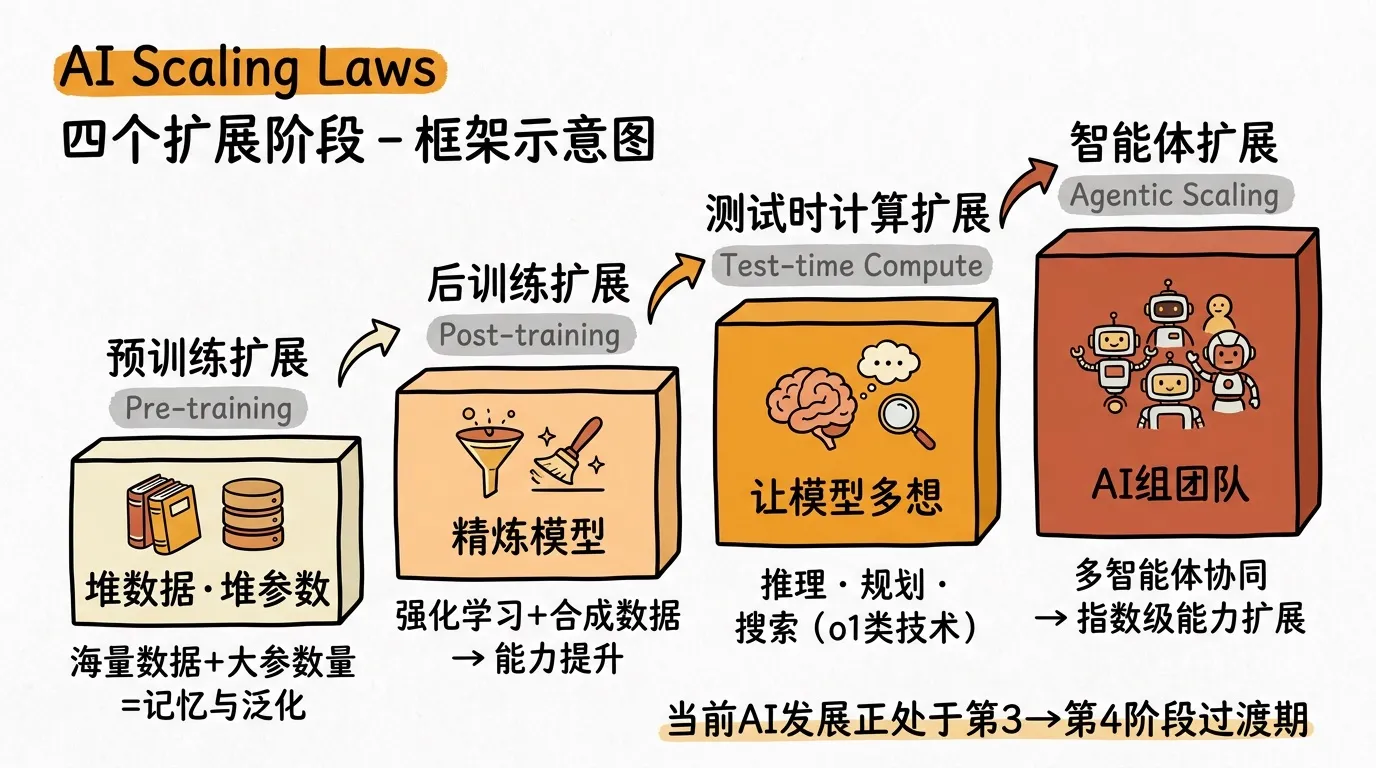
AI 的四个扩展阶段
技术层面,黄仁勋把 AI 的演进拆成了四个 Scaling Law:
第一阶段:预训练扩展。 堆数据、堆参数。大家最熟悉的阶段。
第二阶段:后训练扩展。 用强化学习和合成数据精炼模型,人类数据只是“种子”。
第三阶段:测试时计算扩展。 这是他花最多篇幅讲的。
“Inference is really about thinking… thinking is way harder than reading. Pre-training is just memorization and generalization… but test-time scaling is about reasoning, planning, and search.” (推理本质上是思考。思考远比阅读难。预训练只是记忆和泛化,但测试时扩展是推理、规划和搜索。)
简单说:让模型在回答之前“多想一会儿”,投入更多算力做深度推理。
【注:测试时计算(Test-time Compute)的代表性技术是 OpenAI 的 o1 系列模型,通过“思维链”让模型在回答前进行多步推理。与预训练“读书”不同,这一阶段更像“考场上认真思考”。】
第四阶段:智能体扩展。
“The next scaling law is the agentic scaling law. It’s kind of like multiplying AI… we could spin off agents as fast as you want.” (下一个扩展定律是智能体扩展。就像在复制 AI,我们可以按你想要的速度批量启动智能体。)
不是一个更强的模型,是一群 AI 协同工作。就像给 AI 组建团队。
他还提到,未来十年最惊人的智能体形态不是软件,是人形机器人。
“If I were to create the most amazing agent that we can imagine in the next 10 years, it’d be a humanoid robot.” (如果要我设想未来十年最令人震撼的智能体,那会是人形机器人。)
不再是计算机,是工厂
Lex 问 NVIDIA 最深的护城河是什么。
“Our single most important property as a company is the install base of our computing platform.” (我们最重要的资产,是计算平台的安装基数。)
不是某一代芯片多强,是全球有多少开发者在用 CUDA。这个装机量加上几百万开发者的信任,构成了竞争对手很难撬动的壁垒。
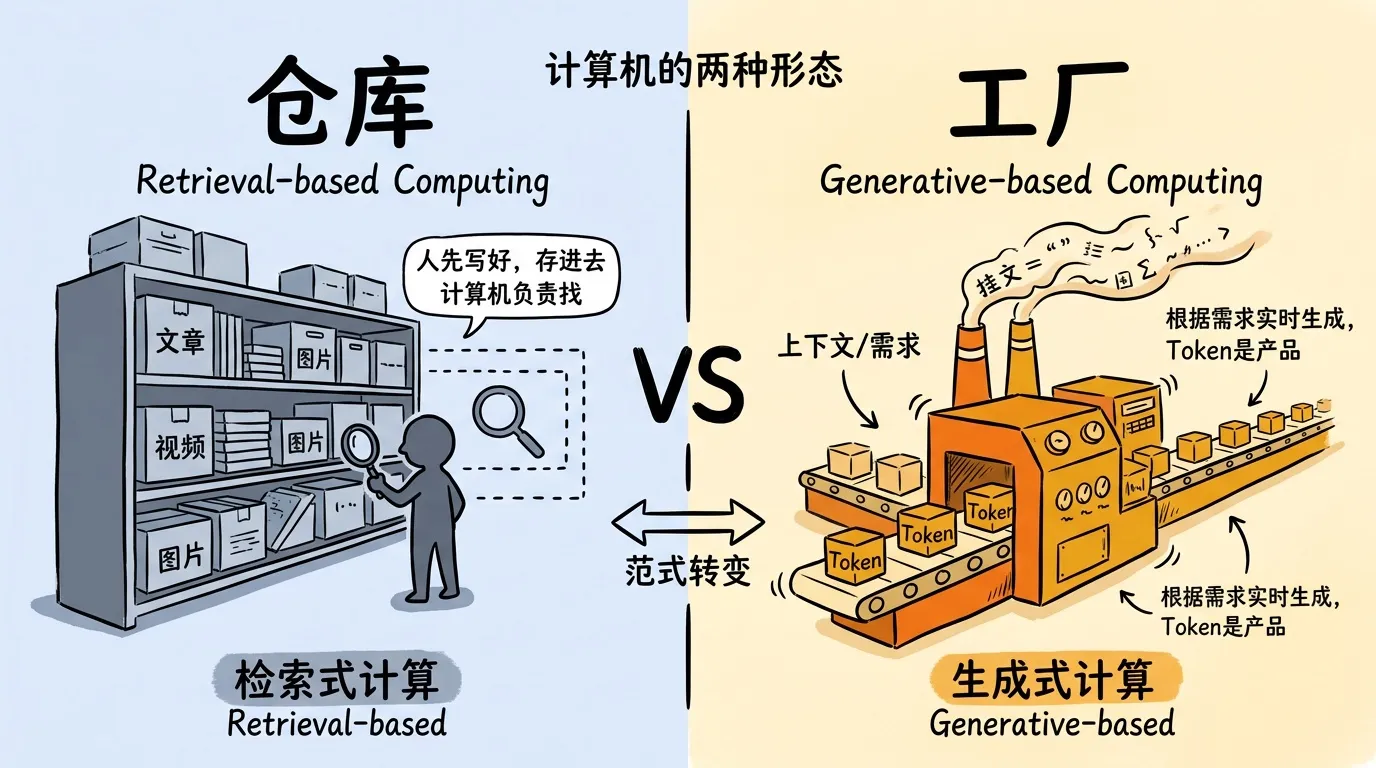
但更有意思的是他对计算本身的重新定义:
“We went from a retrieval-based computing system to a generative-based computing system.” (我们从基于检索的计算系统,走向了基于生成的计算系统。)
以前的互联网是“仓库”:人先写好文章、录好视频,存在服务器上,计算机负责检索和分发。现在的 AI 是“工厂”:计算机根据上下文实时生成内容。
“It’s no longer a computer, it’s a factory. A factory is used for generation of revenues.” (它不再是一台计算机,是一座工厂。工厂是用来创造收入的。)
工厂的产品是 Token。他认为专业领域的 Token 定价可以达到每百万次 1000 美元,未来算力占全球 GDP 的比例将是过去的 100 倍。NVIDIA 成为一家年收入 3 万亿美元的公司,在他看来”当然可能”。
“Nvidia is not in the market share business. Almost everything that I just talked about don’t exist.” (NVIDIA 不是在争份额。我说的这些市场,目前大部分还不存在。)
市值从 80 亿跌到 15 亿,他赌对了
NVIDIA 今天的护城河不是天上掉下来的。
早年黄仁勋做了一个近乎自毁的决策:在所有 GeForce 显卡里强制内置 CUDA。 这让硬件成本直接增加 50%,而当时 NVIDIA 的毛利率只有 35%。几乎把全部利润搭了进去。
“Nvidia is the house that GeForce built, because it was GeForce that took CUDA out to everybody.” (NVIDIA 是 GeForce 建起来的,因为正是 GeForce 把 CUDA 带给了所有人。)
那几年 NVIDIA 的市值从 80 亿美元跌到 15 亿美元。华尔街不理解他为什么要烧钱做一个当时没人用的东西。
黄仁勋赌的是安装基数。
“Install base is everything. Install base defines an architecture.” (安装基数就是一切。安装基数定义了架构。)
几亿游戏玩家手里的 GeForce 显卡,就是 CUDA 的开发者底座。当 AI 浪潮来的时候,全世界发现只有一个平台上有现成的工具链、社区和生态。这就是 NVIDIA 今天的壁垒。
【注:OpenCL 是当时 CUDA 的主要竞争对手,由苹果、AMD 等公司主导的开放标准。技术上并不弱,但最终败在生态规模上。CUDA 赌赢了,OpenCL 现在基本已无人问津。】
他在组织管理上也很极端。60 个人直接向他汇报,不做一对一沟通,所有问题都在多人群体中讨论。
“I don’t do one-on-ones. We present a problem and all of us attack it… because we’re doing extreme co-design all the time.” (我不做一对一面谈。我们提出一个问题,然后所有人一起攻克。因为我们始终在做极致的协同设计。)
一个机架 130 万个组件、4000 磅重、涉及 200 多家供应商。要把这些东西协同起来,一对一聊是不够的。
系统性遗忘:黄仁勋的压力管理术
访谈最后,Lex 问他怎么扛住这种级别的压力。
黄仁勋给出了三个应对方法,每一个都出乎意料地朴素。
把担忧说出来,是第一个。
“Everything that I feel could put anybody in harm’s way, I’ve told someone who could do something about it. So I’ve gotten it off my chest.” (任何我觉得可能出问题的事,我都告诉了能解决的人。这样我就如释重负了。)
不独自扛,不焦虑循环。
第二个是系统性遗忘。
“One of the most important attributes of AI learning is systematic forgetting. You need to know when to forget some things. You can’t carry everything.” (AI 学习最重要的属性之一是系统性遗忘。你需要知道什么时候该忘掉一些事。你不能什么都背着。)
像 AI 训练一样,人也需要“遗忘”过去的失败。失败是经验,但不是行李。
第三个最简单:“这能有多难?”
“I say to myself often… how hard can it be? You don’t want to over-simulate everything and all the setbacks… you want to go into a new experience thinking it’s going to be perfect.” (我经常对自己说:这能有多难?你不要提前在脑子里把所有困难模拟一遍。你要带着“这次会很完美”的心态走进新的经历。)
一个掌管四万亿美元公司的人,压力管理的核心不是什么冥想或方法论,是一种刻意保持的“孩子般的无知”。
两个半小时的访谈,黄仁勋讲了很多,但贯穿始终的是一个判断:AI 不是一个新工具,是一次计算范式的根本转变。 以前计算机帮人检索信息,现在计算机替人生产价值。以前你用工具,未来工具用你的指令自己干活。
他说 NVIDIA 不是在争市场份额,因为他说的那些市场还不存在。
这句话值得认真想想。
想持续追踪黄仁勋对 AI 趋势的判断,关注我,这个系列会一直写下去。
觉得有收获,转发给也在思考这些问题的朋友。