
Karpathy 说不需要 RAG,我试了,他是对的
我尝试过很多次建个人知识库。
Notion、Obsidian、卡片笔记法、Zettelkasten,都试过。每次都是同一个结局:资料收进来,然后卡在整理这一步。分类、打标签、建双链、写摘要,每一步都合理,每一步都很耗时。坚持一两个月,系统越来越重,最后悄悄放弃。
所以当我看到 Karpathy 在 X 上发的那条帖子时,第一反应不是”这个思路不错”,而是”等等,整理这件事谁来做”。
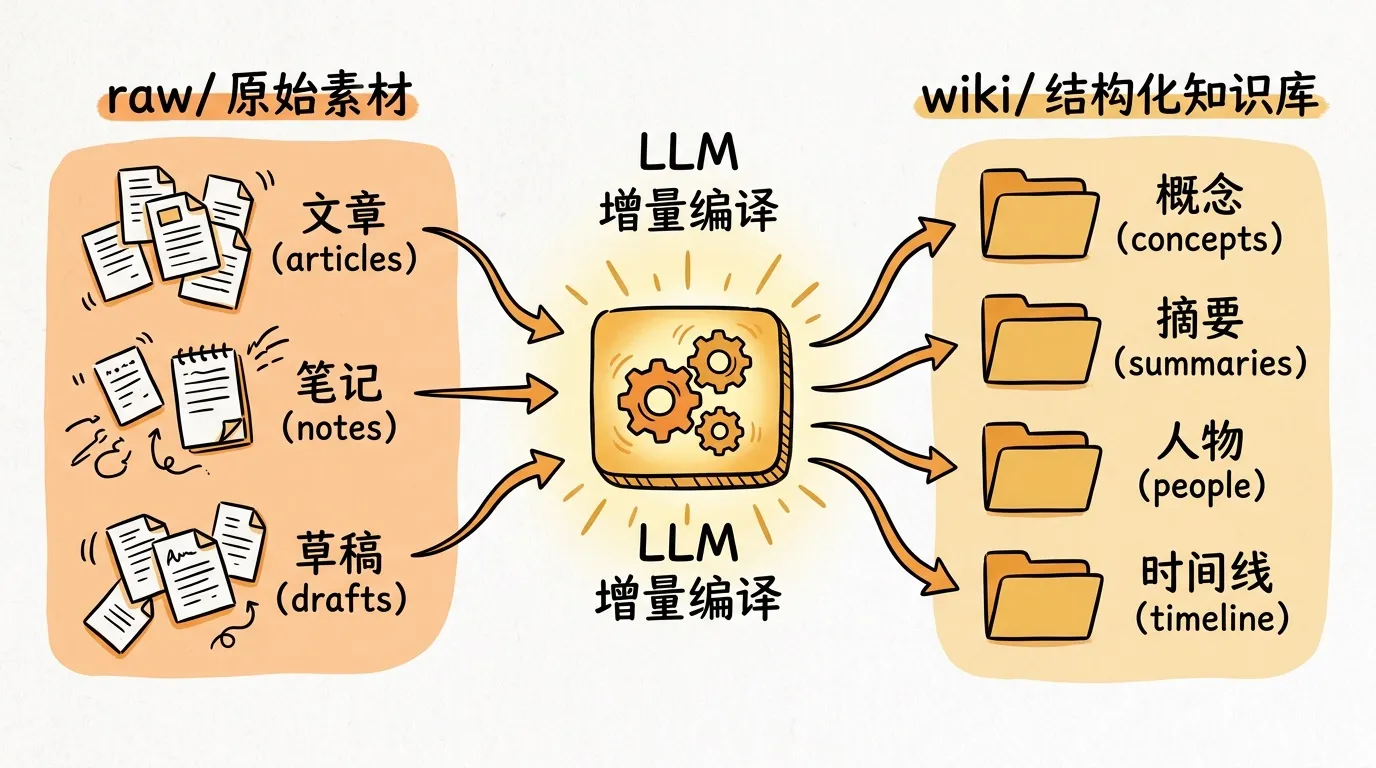
他分享了自己最近的工作方式:把原始资料(文章、论文、笔记)放进一个 raw/ 目录,然后让 LLM 增量”编译”成一个 wiki——摘要、概念、索引、反链全部由 LLM 生成和维护。他用这套方式跑某个研究方向的知识库,已经有 100 篇文章、40 万词。
换句话说,整理这件事,LLM 来做。
你只需要收集,不需要整理。
不需要 RAG 的那部分
很多人一谈到个人知识库,第一反应是向量数据库、向量嵌入、RAG 管道。Karpathy 用的是一个 raw/ 目录和一个 LLM。
方式很简单:原始资料(文章、论文、笔记)放进 raw/,让 LLM 读它们,提炼摘要,归纳概念,维护索引,生成一堆 .md 文件存进 wiki/。之后你的问题冲着 wiki/ 去,LLM 读相关文章来回答。
他特别提到一件事:他原以为到了一定规模要上 RAG,结果不需要。LLM 自己维护索引和摘要,找相关内容完全够用。
这个地方值得停一下。
少楠有个说法:知识是用于生产的信息。RAG 解决的是”怎么检索信息”,但个人知识库真正需要的是”怎么把信息变成能用的知识”。LLM 做的不是检索,是理解和提炼。这是两件不同的事。
在个人知识库这个规模,LLM 能做更聪明的事:不是靠相似度打分找文档,而是读完索引,判断哪些相关,再去读,再回答。过程更像一个人在翻阅自己的笔记本,而不是一台机器在搜索。
25 个批次,219 篇
Karpathy 在帖子最后说,他觉得这里能做出一个很棒的产品,而不只是一堆拼凑的脚本。我用 Claude Code Skills 封装了三个命令,算是朝这个方向迈了一步:
kb-compile:把 raw/ 增量编译进 wiki/kb-query:对 wiki/ 提问,结果存回 queries/kb-lint:检查 wiki/ 的健康状态,找断链、孤立文章、潜在新话题
整个过程在 Obsidian 里完成。raw/ 里的原始资料、wiki/ 里的编译产出、queries/ 里的问答记录,都是 .md 文件,打开 Obsidian 就能浏览。Karpathy 也把 Obsidian 当作他的前端界面,这一点我们不约而同。
今天把历史积累的笔记全跑了一遍。25 个批次,wiki 里最后是 219 篇文章。
不过,喂进去的东西和 Karpathy 的很不一样。他的知识库围绕某个特定研究方向——文章、论文、代码仓库。我喂进去的是三年的个人积累:日记(2022 年到现在)、读书笔记、灵感碎片、AI 领域的精选文章,还有我自己还没发布的写作草稿。不是编译一个领域,是编译一个人。
有一个细节挺有意思:LLM 自己决定了跳过什么。模板文件、只含许可证密钥的笔记、41 个空文件,它判断这些不是知识内容,直接跳过或删除。90 个太短的灵感碎片,被它合并成 3 个聚合摘要。我没有为每种边界情况写规则,是它在编译过程中自己判断的。
他没提到的两个维度
编译完之后,wiki 里有 concepts/、summaries/、connections/,这些 Karpathy 都提到了。
但因为我喂的是个人资料而不是某个领域的论文,我在编译规则里加了两个 Karpathy 没有的维度。
一个是人物档案(wiki/people/)。我在笔记里反复引用的那些人——Karpathy、Jensen Huang、Naval Ravikant、Paul Graham、稻盛和夫、曾国藩——最后编译出了 17 份独立档案。每份档案是 LLM 从多篇原始文档里综合提炼的,核心立场、主要观点、与其他概念的关联全在里面。
同一个人的观点往往散落在十几个地方——播客笔记、书摘、别人文章的引用里。人物档案把它们整合成一个一致的视角。写文章要引用某人的观点时,不是去搜,直接问知识库。
另一个是时间线(wiki/timeline/)。四篇年度认知快照,2023 到 2026 每年一篇。LLM 从我的个人日记和笔记里提炼出每一年的关键认知变化,我没写一个字。
这两个维度是”编译一个人”才会有的产出。领域知识库不需要人物档案,也不需要时间线。但当你的原始素材里有日记、有反思、有对不同人物观点的反复咀嚼,这些维度就自然浮现了。
有了时间线,我能问的问题就变了:我对管理的理解,从 2023 到现在发生了哪些变化?知识库会去读四年的材料,给我一篇对比分析。
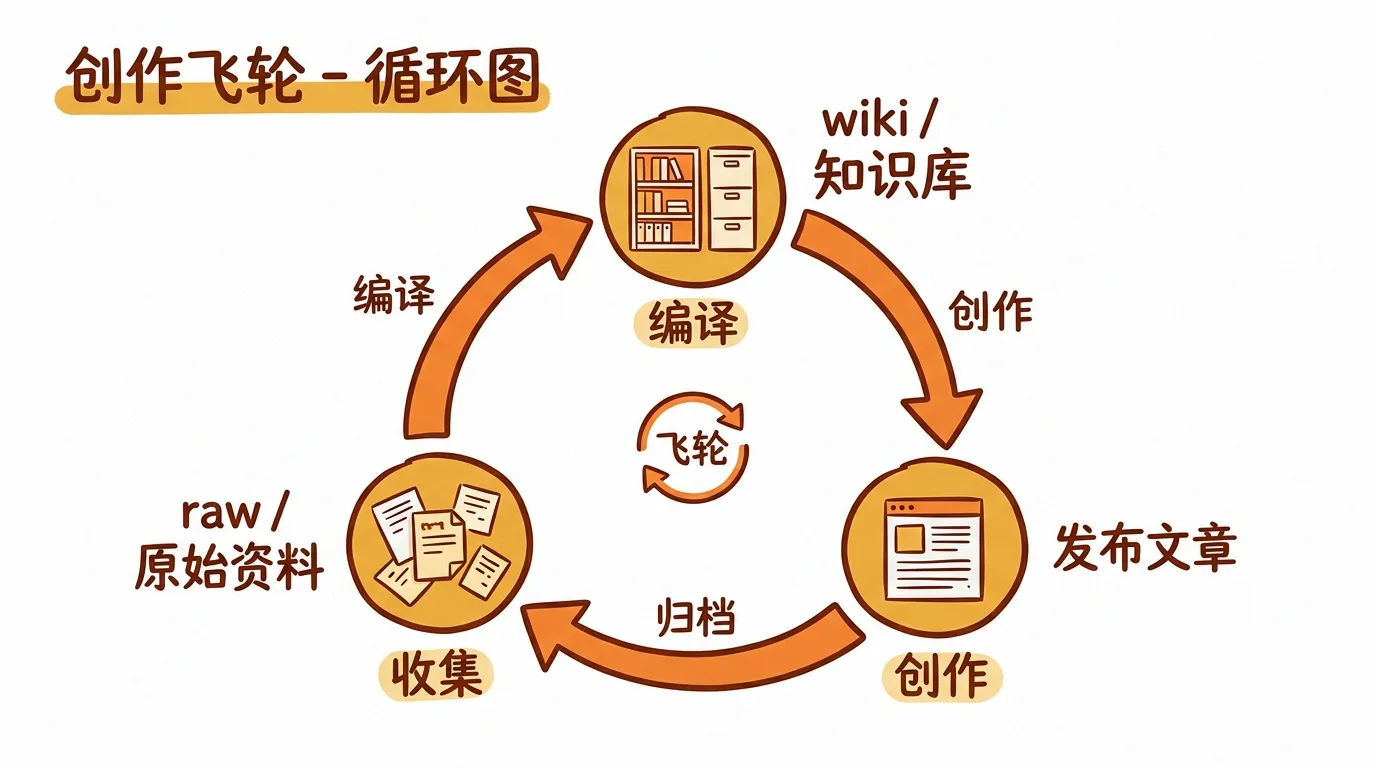
闭环:文章也是原料
Karpathy 提到,Q&A 的输出可以归档回 wiki,让知识库越来越完整。
我把这个循环延伸了一步:每一篇我写完发出去的文章,也会回到 raw/,重新编译进 wiki。
这意味着知识库会知道我用过哪些角度、表达过哪些观点、哪些话题写得多,哪些还没碰过。就像这篇文章,写之前我先问了知识库:“我之前关于个人知识管理写过什么?“它告诉我写过两篇相关的,一篇讲工具选择,一篇讲笔记方法论,但从来没有从”LLM 编译”这个角度写过。所以我知道这个切入点是新的。
外部知识进来,变成文章出去,文章再回来。
这些笔记在 Obsidian 里睡了三年,编译完之后我才知道自己知道什么。
编译完成后,我在 wiki 里查到了一条自己在 2025 年写的笔记:“以输出为火车头带动输入,这才是正确的顺序。”
没想到,我现在搭的这套系统,恰好就是这句话的实现。
原来不是知识不够,是知识没有结构。而给知识加上结构这件事,终于不再需要你自己来做了。
如果你也有一堆沉睡的笔记,关注我,后续会继续分享这套方法的更多细节。