
AI 放大不了你没有的
用 AI 折腾了半年,批量生文、视频号系列、面试辅导,全试了一遍。最后发现 AI 放大的是你已经有的东西,不是你还没有的。
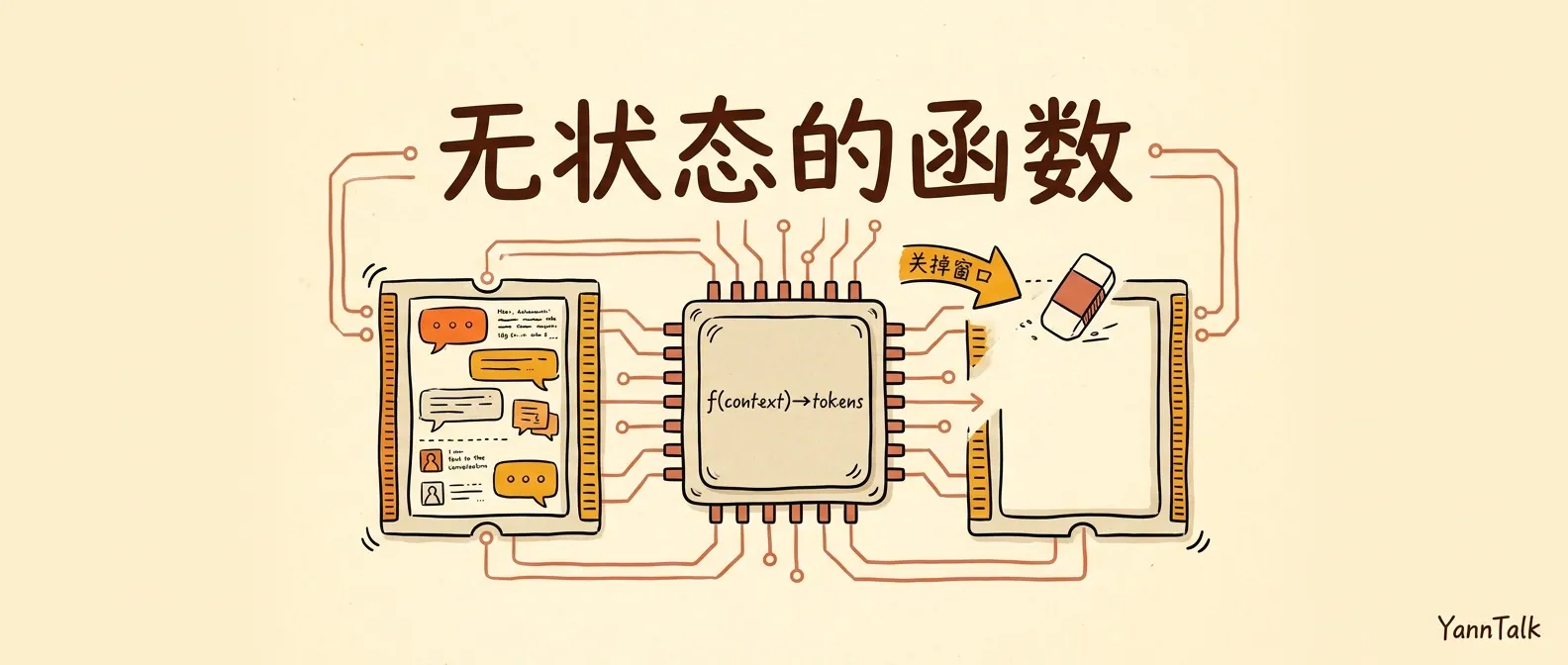
LLM 是一个无状态纯函数:Harness 工程的第一条公理
新窗口里它又问了同一个问题——刚才一起磨方案的那个「它」哪儿去了?LLM 是无状态纯函数,这是 Harness 工程的第一条公理。

AI 为什么时而神准时而乱说?大模型的六个底层机制
费曼讲 AI 阶段一总结。从 Token 到幻觉,用日常类比拆解大模型的六个底层机制,解释 AI 那些看起来矛盾的行为。

不知道怎么用好 AI?答案就在 AI 那里
李笑来分享的递归法:直接问 AI"如何像专家一样使用 AI"。用 AI 来解决"怎么用好 AI"这个问题本身——就像当年你用谷歌搜"怎么用谷歌"一样。

你的 AI Coding 占比多少?面试官追问的才是重点
面试时问 AI Coding 占比,不是为了一个数字。数字背后的方法、踩过的坑、怎么管控质量,才是真正能看出认知深度的地方。

Karpathy 说不需要 RAG,我试了,他是对的
个人知识库试过 Notion、Obsidian、卡片笔记法,都卡在整理。Karpathy 的 LLM 编译模式让整理这件事由 LLM 来做,实测跑了 219 篇,确实不需要 RAG。

AI 之后,工程师靠什么不被替代
从乔布斯斯坦福演讲里的书法课说起,聊聊 AI 时代工程师真正的壁垒不在技能,而在审美和判断力。
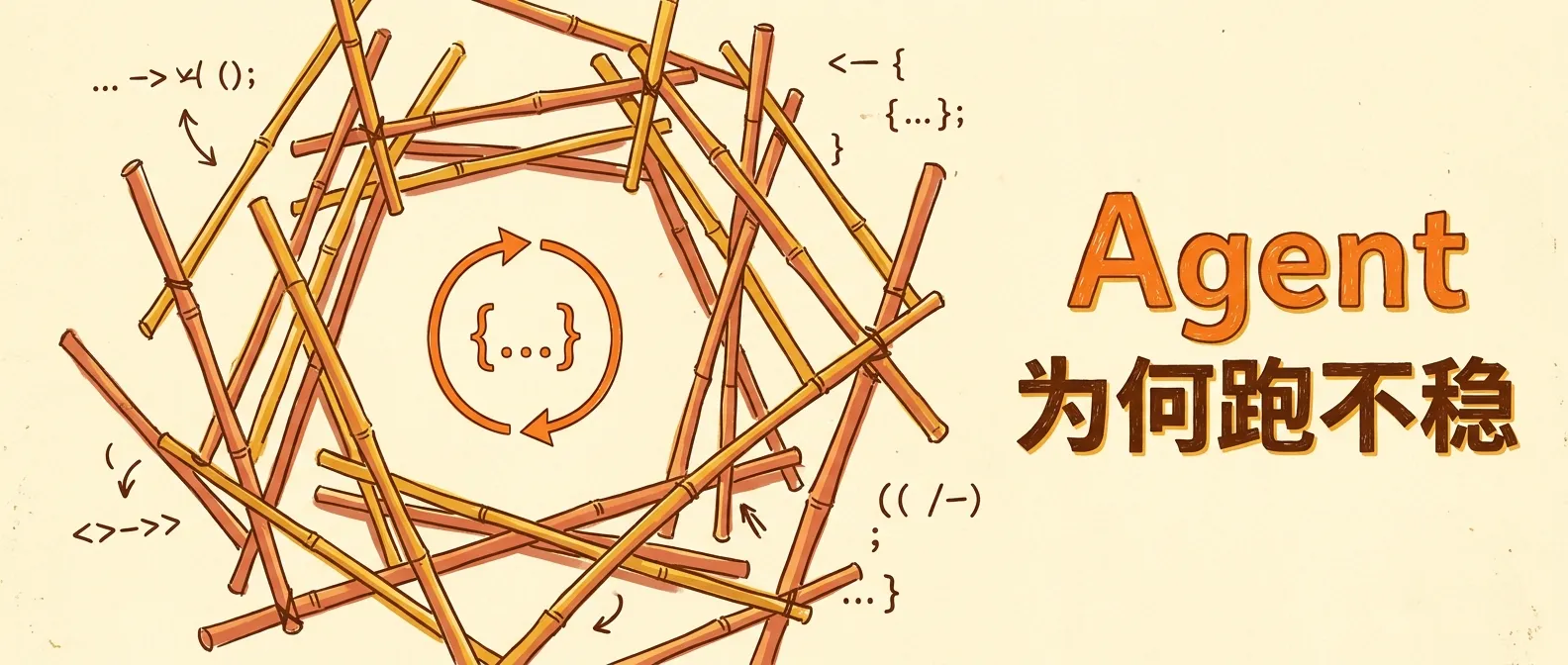
Agent 的核心代码不到 20 行,但大多数团队搭不稳
Agent Loop 的核心实现不到 20 行代码,真正的工程量在 Harness——权限控制、错误恢复、日志追踪这些外围机制。

黄仁勋:AGI已实现,未来每个木匠都是程序员
Lex Fridman Podcast 第 494 期精读。两个半小时里,黄仁勋几乎把 AI 的现状、未来和 NVIDIA 的底牌全摊开了。最具争议的一句:"我认为我们已经实现了 AGI。"

AI 越聊越蠢,不是模型不行,是你把上下文喂脏了
用 AI Coding 工具聊到一半突然犯蠢,不是上下文不够长,是上下文太脏了。工具定义、测试输出、压缩误伤,三层噪声叠加才是根因。